用于自动识别系统的生物特征表征通常是为了获得显著的判别能力而学习的,即生成由不同主体的特征产生的显著不同的特征,同时保持给定用户的适当一致性。尽管如此,可判别性并不是生物特征表示的唯一可取属性。例如,在设计生物特征模板保护方案时,所用模板中系数的相互独立性是一个有价值的特性。事实上,管理具有独立系数的表示可以最大限度地提高可实现的安全性。在本文中,我们提出了不同的学习策略来获得具有统计独立性的系数之间的生物特征表示,同时保持可判别性。为了实现这一目标,采用了不同的策略来训练卷积自编码器。作为概念的证明,通过考虑使用手指静脉和手掌静脉模式的生物识别系统来测试所提出方法的有效性。
表征学习是一门利用机器学习算法从分析的数据中自动获取一组用于特定目的的系数的学科,这些系数通常无法通过直接利用所考虑信号的原始原始形式来实现[2]。例如,可以使用新的数据表示来获得判别特征,即可以有效地用于分类目的的特征[19]。
其中,表征学习的一个潜在应用领域是使用生物特征标识符的自动人物识别,其中最重要的是处理从不同受试者的特征中提取的显著不同的模板,而从同一受试者获得的模板则尽可能稳定[3]。这允许自动识别一个合法的人,并授予对特定商品或服务的物理或逻辑访问权,以及通过评估从获取的数据生成的模板与声称的身份相关的模板之间的相似性来拒绝潜在的冒名者。值得注意的是,虽然可辨别性是运行生物识别系统所需的重要属性,但在解决模板安全和隐私问题时,还需要其他要求[6]。实际上,生物识别标识符的泄露会对生物识别数据的合法所有者造成严重后果,例如无法进一步使用所涉及的模板,或者攻击者可能利用收集到的信息用于不正当目的,例如跨多个应用程序跟踪用户的活动,这些应用程序的访问控制机制依赖于相同的生物识别特征[16]。为了显著降低这种风险,文献中提出了几种生物识别模板保护(BTP)方法。生物识别密码系统是最有效的BTP解决方案之一。它们基于生物特征表示与二进制加密密钥的组合,生成模板表示,即辅助数据,不会泄露两个原始组件的信息[31]。当实现这些方法时,它们对攻击的鲁棒性取决于生物特征模板系数的相互统计独立性。不幸的是,在设计特征提取机制时,这方面往往被忽略,导致所提出应用的实际安全性通常远低于理论安全性[33]。
在此框架下,本文重点设计了自动学习具有相互独立系数的生物特征表示的方法,同时不影响所考虑的表示的可辨别性。更详细地说,本文源于同一批作者[21]的前期工作,这是第一次考虑到这一点。具体来说,[21]中已经引入了几个指标来对生物识别模板中系数的相互统计独立性进行定量评估,并且已经进行了一些尝试来改进来自手指静脉模式的表征的此类测量。与[21]相比,目前的贡献在以下方面推动了技术的发展:
所提出的评估指标和提取独立特征的方法的有效性,在[21]中应用于手指静脉模式,也适用于手掌静脉模式。因此,这里考虑到不同的数据库;
额外的损失,已经在文献中用于不同于这里考虑的目的,用于在进行的实验测试中训练卷积自编码器;
本文介绍了一种新的损失,专门用于训练自动编码器学习相互独立的特征,并基于所采用的独立性评估指标,并在考虑的生物识别模式上进行了测试。
本文组织如下:关于BTP方案的一般信息,以及这里所考虑的生物特征密码系统的具体信息,在“生物特征模板保护”节中给出,其中还强调了生成具有相互独立系数的生物特征表示的重要性。在[21]中介绍的用于定量评估表征独立性的指标在“统计独立性指标”一节中进行了讨论。这里用于生成所需生物特征表示的方法随后在“生物特征表示”一节中介绍。为评估拟议方法的有效性而进行的测试载于"实验测试"一节,而根据获得的结果得出的一些结论则载于"结论"一节。
与依赖密码或令牌的传统方法相比,生物识别数据提供的几个优势之外,在实施基于个人特征的自动识别系统时,还应该仔细考虑几个问题。如前所述,如果攻击者能够欺诈性地收集生物特征,那么就有可能跟踪其合法所有者在不同领域的活动[29]。此外,泄露的数据不能再使用,而且由于可用的生物特征数量有限,无法撤销或补发,因此失去对自己生物特征数据的控制是非常不希望发生的事情。此外,生物特征也可以被分析以揭示其所有者的敏感信息,从而被用于歧视目的[8]。
实际上,欧盟通用数据保护条例(GDPR)指出,生物特征是敏感的个人数据,因此应该进行处理,以确保足够的安全水平。还值得注意的是,对于攻击者来说,收集存储在数据库中的模板可能与获取原始生物识别数据一样有效。事实上,已有研究表明,几种生物特征标识符可以从其表示(即模板)中充分重构原始生物特征[28],并且当使用神经网络获得所使用的特征时,也可以执行这种反向过程[20]。
因此,在设计生物识别系统时,为了解决上述问题,采取适当的对策是至关重要的。
可以用来保护数据库中存储的模板的一个简单解决方案是使用某种加密算法对数据进行加密。这种方法的缺点是在识别过程中需要对模板进行解密,这是一个系统漏洞[31]。同态加密已经被用来解决上述缺点,通过在加密域中实现识别步骤,而不暴露模板。虽然这种解决方案可以有效地保护所使用的生物特征数据,但所涉及的处理的计算复杂性通常相当高,因此不适合许多应用。此外,采用同态加密通常涉及负责管理数据交换的安全服务器的可用性,这代表了在实际场景中需要考虑的另一个约束。
生物特征模板保护方法的设计已经成为使用同态加密的可行替代方案,以确保在识别过程中对生物特征的安全和私密处理。通常,这些方法生成一个受保护的模板,该模板不会泄露任何关于原始数据的信息。识别过程可以在这样的安全域中进行,从而在整个识别过程中对数据进行保护。根据ISO/IEC 24745标准[15],BTP方案应满足以下属性:
不可逆性:给定一个受保护的模板,原始生物识别样本或从其衍生的任何未受保护的表示都不应该被重建[22];
可再生性:从给定的生物识别样本或表示中,应该可以发布多个受保护的模板;
不可链接性:给定两个受保护的模板,从相同的生物识别样本或表示中生成,并存储在不同的应用程序中,不应该确定它们属于同一主题;
性能:使用BTP方案不会显著影响系统识别性能[27]。
传统上,BTP方案分为两大类:可取消生物识别[23]和生物识别密码系统[22]方法。
前一类包括将转换应用于生物特征数据或其表示以保护其的方法。可逆转换的使用导致了盐渍方法,其安全性依赖于定义所使用转换的参数的秘密存储。相反,当假设攻击者可以获得所使用转换的知识时,必须考虑不可逆函数才能正确定义BTP方案[24]。虽然可取消的生物特征已经被定义为几个最常用的特征,如指纹[34],面部[5]和虹膜[26]等,但它们的不可逆性很少通过详尽和严格的证明来评估,因为在证明功能对任何可能的攻击的实际不可逆性方面存在内在困难。
另一方面,生物特征密码系统可以区分为密钥生成方法和密钥绑定方法,密钥生成方法从考虑的生物特征数据中提取加密密钥[32],密钥绑定方法的目的是通过生物特征数据来保护加密密钥,反之亦然,将两个信息源组合成通常称为辅助数据的二进制模板[11]。前一种方法通常不能提供适当的可再生性和不可链接性,因为需要与生物特征数据不同的信息来生成相同特征的多个表示。在所有可能的BTP方案中,键绑定方法无疑是研究最多的方法。更详细地说,密钥绑定方法的安全性已经成为几项严格评估的对象[29],深入的信息论研究试图准确评估在将考虑的生物特征表示与加密密钥绑定时获得的模板中泄露的原始秘密源的知识量[14]。必须指出的是,针对键绑定BTP方案的攻击的鲁棒性通常是在假设所采用的生物特征表示由相互独立的系数组成的情况下进行研究的。在此假设下,键绑定方案生成的二进制助手数据具有最大的熵,存储模板的信息泄漏分析可以考虑单个系数,并扩展到对整个可用特征集的结论。不幸的是,大多数生物识别系统中采用的参数表示通常由强相关特征组成,其结果是设计的密码系统的安全性损失越大,可用数据距离相互独立的理想条件越远[33]。
因此,在设计绑定密钥的生物识别密码系统时,具有相互统计独立特征的表示的生成与具有高度判别性的模板一样重要。在本文中,我们依赖于[11]中一些作者提出的生物识别密码系统,并在以下段落中进行了详细介绍,其中也总结了评估其有效性的最重要方面。
图1
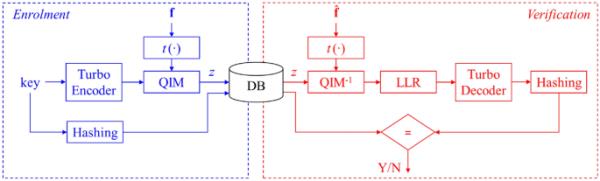
[11]提出的零泄漏密钥绑定方法
[11]中提出的密钥绑定方案是一种受数字调制范式启发的代码偏移方法,专门设计用于保证在适当的情况下,不会从存储的帮助数据的知识中泄露所使用的加密密钥的信息。考虑的BTP方案如图1所示。
在这个生物特征密码系统中,一个秘密二进制密钥与一个生物特征表示(包括m个系数)一起被处理,在合法用户注册期间提供。该方案的零泄漏能力是通过使用逐点函数来实现的,该函数应用于生物特征表示的每个系数,以便从每个系数中导出一个具有概率密度函数的变量,该变量遵循由滚转参数描述的凸起余弦分布。实际上可以证明,在所使用的表示中特征相互独立的假设下,使用这种转换可以保证所存储的辅助数据不会泄露所使用的加密密钥的任何信息,从而实现零泄漏保护方案[11]。
为了产生要安全存储在系统中的辅助数据,通过用纠错码对输入的二进制加密密钥进行编码,得到一个字符串q,该字符串包含m个大小为一个字母的相移键控(PSK)星座的符号。如图1所示,在所采用的实现中,涡轮码被用于实现这一目标。然后执行量化索引调制(QIM)过程,通过计算代码偏移辅助数据来绑定所考虑的二进制密钥和生物特征表示。
当用户希望被系统识别时,则执行相反的过程。具体来说,使用新获得的生物特征表示,将反向QIM应用于存储的辅助数据z。如果新的生物特征表示与用户注册期间提取的表示接近,则获得的消息与注册时的消息相似,因此可以通过基于对数似然比(LLR)标准的软解码过程来检索原始二进制密钥。相反,如果验证过程是由冒名顶替者执行的,则原始消息和相关的原始密钥就不能重构。将所使用的密钥存储在散列版本中,可以将重建的数据与原始数据进行比较,而不必透露它们,从而根据识别过程中涉及的主题的身份做出决定。
如前所述,在具有相互独立系数的生物特征表示的情况下,所考虑的方案不会从助手数据z泄露有关所使用的加密密钥的任何信息。在评估所采用的键绑定方法的有效性时,必须考虑的其他方面包括:
从存储的助手数据的知识中泄漏有关所使用的生物识别表示的信息。这方面通常表示为隐私性(P),可以通过估计攻击者在尝试重建输入生物特征表示时可能犯的最小重建误差来评估,给定存储的辅助数据z。如[11]所示,所采用的提升余弦分布的滚降值越大,所提出方案的隐私性就越好;
受雇生物识别代表的能力(C)。这方面考虑了可以与所使用的生物特征表示绑定的加密密钥的最大大小。显然,可以嵌入到所考虑的模板中的位越多,系统对暴力攻击的鲁棒性就越高。滚转参数的较大值会对可实现容量产生负面影响。
由于所提出方案的隐私和容量是一种权衡关系,取决于的选择,因此[11]提出了一种迭代选择策略,所使用的参数确定为可实现容量最大化,同时保证可接受隐私的最低水平,通常设置在95%到99%之间。
[21]中提出的统计独立性指标根据图2所示的框架定义。具体而言,采用Hilbert-Schmidt独立准则(HSIC)统计检验[10]来计算与所考虑的表示中每对可用特征相关的度量。然后使用图论[4]衍生的度量来提供所需的定量评估,评估所分析的表示中系数的总体独立性水平。
图2
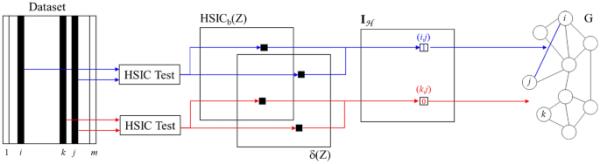
统计独立性评估框架的可视化描述,改编自[21]
更详细地说,为了评估给定表示的独立性,假设有一个生物特征模板数据集,每个模板表示为长度为m的特征向量,从u个受试者中收集,总共有n个样本。如图2所示,这些数据可以排列成一个矩阵,每一行是一个生物识别模板。
给定任意一对由随机变量和表示的两个特征,HSIC检验估计感兴趣的总体的平方Hilbert- schmidt范数,即,其中为联合分布,和为两个再现核Hilbert空间(RKHS)。定义HSIC检验的原假设和研究假设如下:
(1) (2)
也就是说,在两个独立随机变量和的情况下,原假设不能被拒绝。
给定一个观测样本,所使用的框架中使用的统计量以有偏的形式估计如下:
(3)
即通过运算符计算得到的方阵主对角线上元素的和为矩阵的乘积,,,其中表示n个1的向量,另外两个矩阵定义如下:
(4)
用和表示所考虑系数的方差。
设置显著性水平作为第一类误差的上界,得到经验估计的渐近分布,该分布的分位数表示为,可以作为确定检验结果的阈值。当两个随机变量在本例中为独立时,零假设不能被拒绝。
一旦对可用的m维生物特征表示中的每一对可能的系数进行HSIC检验,就可以得到如下的方形对称独立矩阵:
(5)
其中和表示任意两个可能的特征,。
得到的二元独立矩阵可以解释为一个邻接矩阵,与一个独立无向图相关联,当相应的系数相互独立时,其边E连接节点V。有了这样创建的图,就可以通过利用图论的概念来定义几个表示给定表示的整体独立性水平的指标。[21]中提出了以下指标,并在以下讨论中使用这些指标来比较本文提出的生成独立系数表示的方法:
归一化边数:图G中的边数,对与G节点数m相同的完全图的最大边数进行归一化,即。计算值可以解释为独立系数的百分比。这个度量很容易计算,但它可能传达的信息价值不大。例如,的值并不意味着特征在统计上是相互独立的,而仅仅意味着独立矩阵包含了酉项;
归一化最大团大小:G的团被定义为其中每两个不同节点相邻的完备子图。如果一个团不是另一个团的子集,它也被称为最大团,如果它有最多的节点,它也被称为最大团。给定从独立矩阵得到的图G,其最大团的大小S可以作为表示独立性水平的度量,一旦对最大可能值进行归一化,即。这个度量给出了一个有效的独立性度量,因为最大团中的特征实际上是相互独立的。尽管如此,它可能经常导致非常低的值,因此在通过它在试图最大化特征独立性的不同方法之间进行比较时存在困难。此外,它的计算可能需要大量的处理时间,特别是当考虑的特征数量m很大时。此外,从一个图中可以得到多个最大团,这使得很难理解其中哪个是最好的;
归一化度中心性:图G中节点i的度中心性是通过节点本身的边数来计算的。这个数量表示图中每个节点的重要性,以及所考虑的场景中每个系数与其他系数的独立程度。它可以用归一化的形式除以图的最大可行度,即。在执行的测试中,计算的度量不是将每个节点获得的值相加以获得单个总体度量,而是按降序组织形成一条曲线,从而显示与只有相互独立特征的理想场景的偏差,所有可用节点的归一化中心度为1。这样的表达式可以更容易地指示更重要节点的数量,即独立于大多数其他系数的特征。
摘要
介绍
生物识别模板防护
有限公司
考虑生物识别密码系统
统计独立性
生物特征表示
实验测试
结论
数据可用性
参考文献
作者信息
道德声明
相关的内容
搜索
导航
#####
考虑到测试旨在生成具有相互独立系数的生物特征表示的策略的场景涉及使用深度学习策略来处理手部静脉模式。更详细地说,正如“实验测试”一节所具体说明的那样,通过本节所描述的方法,可以生成手指静脉和手掌静脉模式的生物特征表示。
基于手部静脉的生物识别系统依赖于我们手腕、手掌、手指和手背血管模式的独特性[37]。由于血红蛋白的吸收特性,实际上可以通过非侵入性和非接触式设备获取描绘皮下静脉模式的图像,只需用波长在700至900 nm之间的近红外(NIR)光照射它们[30]。因此,在传输或反射模式下工作的捕获设备可以产生图像,其中血管看起来很暗,而周围的组织让光线通过,反而更亮[25]。
图3
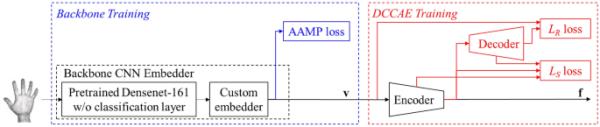
提出了一种基于自编码器的方法来创建具有相互独立系数的生物特征表示,同时保持区分能力
所提出的创建具有相互独立系数的表示,同时仍保持适当判别能力的方法如图3所示,该方法依赖于级联神经网络,由以下部分组成:
基线系统,其目的是生成适合在开放条件下用于核查任务的表示;
一种密集连接的卷积自编码器(DCCAE),其目的是估计基线系统产生的特征的内部表示,同时最大化派生系数的相互独立性。
表1来自Densenet-161的主干CNN嵌入器
更详细地说,由于基线系统应该处理静脉模式以创建用于验证应用程序的鉴别模板,因此该组件的设计遵循[17]中提出的方法,即使用源自DenseNet-161[12]的卷积神经网络(CNN),并添加如表1所示的自定义层集,创建包含1024个特征的生物特征表示。基线系统使用具有加性角边际惩罚(AAMP)[9]作为客观损失的交叉熵函数进行训练,以定义具有适当判别能力的表征,该表征也可用于与训练过程中使用的特征不同的受试者[17]。
一旦定义了能够区分不同主体的特征,所提出的方法试图估计具有独立性附加特征的替代表示。自动编码器被用于这项任务,利用它们自动学习输入数据的有效编码的能力,目的是保证内部表示具有一些特定的属性,例如稀疏性或紧凑性,同时保留考虑的输入的所有信息内容。具体而言,所执行的测试中使用的自编码器是[18]中提出的DCCAE。如表2所示,它共由55层组成,内部编码由256个系数组成,这些系数来自于输入的1024个系数。
表2采用DCCAE
所使用的DCCAE是通过最小化损失函数来训练的,损失函数定义为,是一个超参数,代表重构损失,通过余弦不相似度计算
(6)
为基线CNN生成的第i个特征表示,为自编码器重构的对应特征表示,B为采用的批处理大小。
相反,自编码器损失的组成部分被定义为学习具有相互独立系数的内部表示。在进行的测试中,通过使用几种不同的方法来达到这一目的,依据如下:
基于Kullback-Leibler散度(KLD)的损失,定义为
(7)
式中为作为DCCAE输入时,DCCAE的第h个隐藏层的第j个激活输出,其中,为第h个隐藏层的激活单元个数,为稀疏度参数。该集合表示内部编码器和解码器专用的DCCAE层数,其中DCCAE如表2所示;
基于L1距离的损耗,定义为
(8)
其中,类似于,仅考虑编码器中最后两层和解码器中的前两层的激活输出来计算所需的损失;
基于谱限制等距特性(spectral restricted isometry, SRIP)[1]的损失,根据所提出的DCCAE的每个卷积层的权重计算为
(9)
式中为第h层权重的矩阵,I为单位矩阵,为谱范数,定义为的最大奇异值。这种损失迫使网络的权重接近正交,从而有可能使学习编码的系数相互独立;
基于DeCov[7]正则化的损失,即通过正则化操作最小化隐藏激活的交叉协方差的方法。考虑到所使用的产生内部编码的DCCAE的第h层及其激活,通过计算得到感兴趣的交叉协方差,对于所有可能的激活对j和k,
(10)
为激活度j在批次上的样本均值,即
(11)
然后计算DeCov损失为
(12)
弗罗本纽斯规范在哪里?这种损失应该允许学习非冗余表示,因此可能提高相互独立性;
基于“统计独立性度量”一节中讨论的HSIC统计检验的损失。这里特别提出了这种新颖的损失,目的是通过将其包含到所使用的损失函数中,来生成优化“统计独立性度量”节中提出的独立性度量的表示。对于网络训练中考虑的一批样本,对自编码器内创建的内部编码中所有可能的系数对,计算式(3)中的HSIC全局统计量,损失计算为
(13)
,所考虑的DCCAE自编码器的内部编码对应于第27层的激活,即。在这种损失的实现中,计算如Eq.(4)所述的HSIC统计量所需的系数的方差被设置为超参数,因为在自编码器训练期间考虑有限的批大小时,否则会获得不准确的估计。
如前所述,本文提出的用于生成具有相互独立特征的生物特征表示的方法已经在依赖手部静脉模式的识别系统中进行了测试。更详细地说,我们考虑了手掌静脉和手指静脉的特征,分别利用了PolyU-P多光谱数据集[36]中的手掌静脉样本和SDUMLA数据集[35]中的手指静脉数据。PolyU-P数据库包含从250名受试者中收集的左右手掌静脉图像,在每个用户的2个记录会话中各收集6个样本。SDUMLA数据库包含来自106个受试者的636个手指的手指静脉图像。在一次会话中,从左手和右手的食指、中指和无名指各采集了6张灰度级BMP格式的图像,分辨率为320240像素。对于每个数据库,用户的不同手指和不同手被视为不同的类。可用的数据被分成两个大小相等的不相交的数据集,一个用于训练所考虑的体系结构,另一个用于执行所需的评估,其中的训练数据保留用于所有数据集中的验证。在考虑开集验证场景的情况下计算识别结果,在训练期间使用一半可用的类,其余一半用于测试。由于PolyU-P数据库包含在多个会话中收集的数据,因此注册和验证的数据取自不同的会话,以避免偏差效应。表3总结了所使用的数据库的特征,以及所应用的实验协议的详细信息。图4描述了从两个数据集中获取的样本示例。
当应用执行的处理时,所有考虑的样本在被馈送到所使用的网络之前都被重新调整为像素,其第一阶段由Densenet-161架构给出,并归一化为零均值和单位方差。使用随机动量梯度下降(SGDM)和批量大小为64的网络进行训练。使用PyTorch 1.1.0进行了测试,系统配置为32Gb RAM,两个nvidia Titan V显卡,i7-3.4GHz处理器,windows stm 10操作系统。
表3使用静脉数据Ses和对应结束实验方案
图4

考虑静脉图像的例子。SDUMLA的手指静脉样本;b u - p掌静脉样本
表4和表5分别对在SDUMLA和puu - p数据库上进行的测试进行了对比分析,对比分析了在“生物特征表征”节中提出的方法在创建通过NEC和NMCS指标表示的独立系数模板的能力。指标NDC在图5中报告,图5显示了所有考虑的节点(系数)的行为,以便更好地说明所有值设置为1时与理想条件的偏差。
表4 SDUMLA数据库中指静脉样本生成的生物特征表征统计独立性的比较分析se
表5 u - p数据库手掌静脉样本生成的生物特征表征统计独立性的比较分析se
上述所有结果都是通过选择所使用的DCCAE自编码器的超参数来获得的,对于每个考虑的损失,目的是保证在生成的表示的独立性方面可以实现最佳性能。在执行计算“统计独立性度量”节中描述的独立性度量所需的HSIC检验时,采用了显著性水平。对使用的骨干CNN嵌入器生成的特征应用独立分量分析(ICA)[13]获得的模板也对所采用的独立性度量进行了评估,ICA等标准方法被认为是基于自动编码器的方法的替代方案,用于创建具有独立系数的生物特征表示。更详细地说,在执行的测试中采用了FastICA方法,该方法对预白数据应用正交旋转,以便最大限度地测量非高斯性。
可以观察到,对于SDUMLA和puu - p,基于KLD、SRIP和HSIC损耗的拟议方法能够在NEC、NDC和NMCS方面提供改进,而不是使用通过基线网络获得的表示。尽管如此,ICA转换仍然保证了稍好的独立性。然而,在提出的基于dccae的特征生成方法中使用DeCov或L1损失可以实现比ICA进一步的改进,该方法依赖于DeCov代表迄今为止为SDUMLA创建具有独立系数的模板的最佳解决方案,并且与PolyU-P上的L1相同。
图5
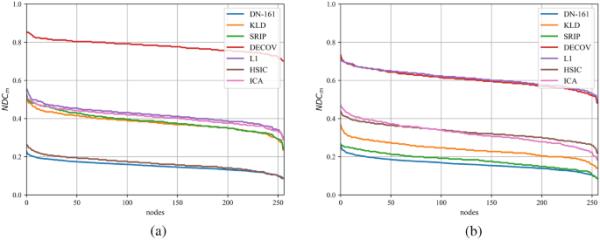
为考虑的表示计算归一化度中心性(NDC)。SDMULA;b PolyU-P
图6
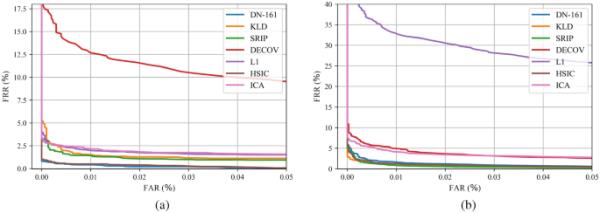
DET曲线报告了使用所考虑的表示可实现的识别性能。SDUMLA;b PolyU-P
除了根据可实现的特征独立性分析所提出的模板生成方法外,还评估了与生物识别密码系统设计相关的其他方面。利用通过所提出的方法生成的生物特征表示可以实现的识别性能,以错误拒绝率(FRR)和错误接受率(FAR)表示,如图6的检测误差权衡(DET)曲线所示。可以注意到,在提出的DCCAE中使用SRIP、KLD和HSIC损耗保证了与基线网络相似的结果,而使用DeCov和L1损耗,甚至使用ICA转换,可能会显著影响可实现的识别率。值得注意的是,报告的结果是在训练提议的基于DCCAE的体系结构时获得的,目的是最大化所创建的表示的特征独立性,因此在学习所使用的DCCAE的参数时不涉及可实现的性能。观察到的行为证实了生物识别密码系统中通常存在的权衡,其中安全性方面的改进(通过获得的独立性表示)可以以识别性能恶化为代价来实现。
值得注意的是,如果生成的表示在生物识别系统中使用,例如在“考虑的生物识别密码系统”一节中考虑和总结的生物识别系统,零泄漏要求必然将系统设置为ZeroFAR,即FAR=0%的操作条件。考虑到6中的图,以及图5和表4和表5的独立性结果,DeCov损失可以作为创建具有独立系数的模板的最可靠选择,同时保证FAR=0%时可接受的FRR值。
图7
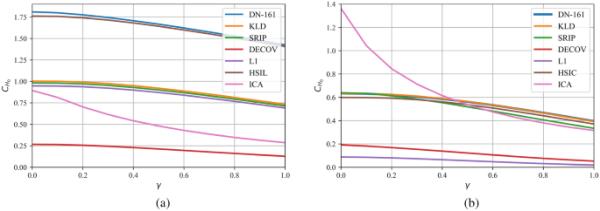
所考虑的表示可实现的平均嵌入容量。SDUMLA;b PolyU-P
图8
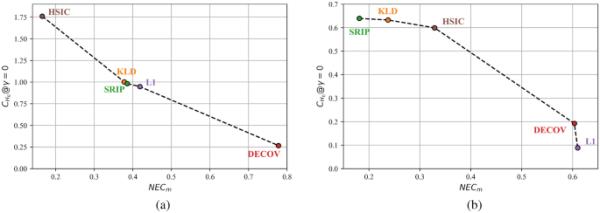
信道容量(平均嵌入比特数)和独立性(用NEC表示)之间的权衡。SDUMLA;b PolyU-P
可以实现的系统安全性也可以通过估计所采用的表示的容量来评估,如图7所示,根据可以嵌入在所生成表示的每个系数中的二进制字符串的平均位数来报告。如[11]中详细介绍和“所考虑的生物特征密码系统”小节所述,可实现的容量取决于所考虑的生物特征密码系统中所采用的升余弦分布的滚转参数。在图中还可以看到不同方面之间的权衡,就可实现的独立性而言,提供最佳性能的方法具有较低的容量值。对于所有提出的基于dccae的表征学习方法,可以通过图8中测量的平均容量(最高可能的容量值)与可实现的独立性(以NEC表示)的关系来清楚地揭示这种关系。可以看出,只要所生成特征的独立性增加,可实现容量就有单调下降的趋势。
本文分析了用独立系数生成生物特征表征的可能性。为此,提出了一种基于自编码器的方法,该方法可以根据不同的损失函数进行训练。根据具体定义的指标来评估可实现的特征独立性,对所提出的方法的性能进行了评估。在包含手指静脉和手掌静脉模式样本的两个不同的生物特征数据库上进行的实验测试表明,所提出的方法实际上能够显著提高所采用表征的独立性,同时保持适当的区分能力。更详细地说,考虑的两个损失函数允许生成具有更高独立性的生物特征表示,而不是诉诸ICA转换时所能实现的。已经观察到,所寻求的特征独立性通常与可实现的识别率和平均嵌入容量之间存在权衡关系。
下载原文档:https://link.springer.com/content/pdf/10.1007/s42979-023-01974-z.pdf
为您推荐:
- PJ Harvey七年来首次踏上北美巡演之旅 2025-07-20
- 奥卡拉有两名男孩失踪,由于父亲的行为被认为有危险 2025-07-20
- 由于缺少选票,布莱克斯堡的手写获胜者仍未确定 2025-07-20
- 汤加接待英联邦秘书长 2025-07-20
- 3R:警察在竞选期间记录政客的演讲 2025-07-20
- 使用卷积自编码器学习具有相互独立特征的生物特征表示 2025-07-20


